The Project
We are five scientists from four disciplines (sociology, political science, computer science, and management science) and have started this Corona Project on February 12, 2020. This was just a few weeks before the so-called “Chinese pandemic” grew into a “global pandemic”, shifting our positions from the observer viewpoint to an affected group.
Despite great advances in data collection, we are still at the beginning of analyses, partly due to the dramatic escalation of the situation, which in turn multiplies the data and the dynamics therein. However, we still want to provide a glimpse into our first pre-analyses by documenting our progress of findings.
Team: Viola Dombrowski, Oul Han, Marc Hannappel, Matthias Kullbach, Lukas Schmelzeisen
Background and aims
The starting point of our research is the timeline of events, which begins with the passing of information regarding several cases of unexplained pneumonia to the WHO bureau in Beijing (see the WHO Situation Report 1). Within just a few weeks, this event has developed into the phenomenon known as the Corona pandemic (see WHO Situation Report 51), and has been dominating discourses and debates worldwide ever since.
At the outset of the pandemic, in parallel to the spread of the novel disease COVID-19, we are also witnessing the dynamic of insights and facts, but also of speculations. In other words, this outbreak that can be defined as a “risk event” according to Keller (2011) entails an unprecedented media spectacle (Kellner 2018). This becomes evident on the one hand by the increase of newspaper articles (for the online presences of the leading German newspapers BILD, SZ and FAZ since mid-March: more than 600 articles per day) and, on the other hand, by the relative frequency in contrast to other topics in the news (for instance on April 8, 81 of 118 news articles on FAZ online regard the pandemic).

Accordingly on social media networks as well, the novel Corona virus became a central topic, possibly in unprecedented variety. Aside from veritably creative Tweets that communicate how to deal with the situation or the guidelines by public bodies, there is also no shortage of Twitter-typical actors who spread pseudo-scientific arguments or borrow from conspiracy theories. The latter group caused the WHO to found a social network team in order to counter misinformation via evidence-based reporting. This initiative also had the effect of attracting the attention of traditional media onto Twitter-based discussions.
Our project aims to examine the discourses in various public arenas, according to the following criteria:
- Firstly, we will systematize the discourses by topic and document the trajectory of the topics on a timeline (method: word frequencies and topic modeling, with theoretical reference to Keller). In this manner, we strive to visualize which topics at which times stood in which relation to ongoing external events (the first infections, the first deaths, curfews, food shortages, etc.) in the traditional media as well as on Twitter.
- We will use the results of this first phase of analysis in order to examine any reciprocal structures between traditional media (here: BILD, FAZ und SZ), social networks (here: Twitter) and „fact producers“ (here: WHO). The objective will be to show the mechanisms of various information transformation processes. Hence, we focus on which institutions, organizations, or actors set the topics on the media discourses’ agenda (theoretical reference: agenda setting theory).
- Finally, we utilize qualitative evaluation procedures in order to understand how the different discourses are influenced by the “objectively knowable” development of the pandemic, with the aim of highlighting the independent dynamics.
Method:
For the approach we implement and follow an “explanatory sequential design” according to Schoonenboom and Johnson (2017), whereby we combine quantitative and qualitative methods in an iterative process. We start out by automated data collection and evaluation methods that are based on the currently oft-discussed field of Computational Social Science. With the help of a Python-based web scraping algorithm, we have created a data set that comprises all online articles of the newspapers BILD, SZ and FAZ that are listed by the keyword „corona“ and have been published since December 31, 2019. Further, we collected all German Tweets that contain the hashtags #corona, #coronavirus, and #covid19 (for more details, see Schmelzeisen (2020)).
For evaluating this high-volume data, we employ a wide span of approaches such as the quantitative analysis of different topics and their development across the trajectory of the pandemic, as well as the qualitative-reconstructive evaluation of discursive dynamics via the critical points that have been identified as such. The quantitative evaluations therefore show us which topics have been centrally discussed, when these topics appeared in both media formats, and in which (numeric) intensity. Since these analyses do not indicate the manner and mode of the public negotiation of the topics, we integrate a sociological discourse analysis at this step.
In this manner, we triangulate the shortcomings of algorithmic methods such as topic modeling with the help of interpretive methods. Thus, quantitative and algorithmic methods allow interesting insights on statistical distributions (Stier/Posch/Bleier/Strohmaier 2017), but no deeper insight into the structures of meanings in communicative processes. The quantitative results offer therefore a means to delimit the findings by topic and time, and further aid the structuring of data where it could not be possible otherwise.
Insights: Current results
Analysis of day-wise frequencies in news articles and Tweets in relation to events regarding COVID-19 (research aim 1):
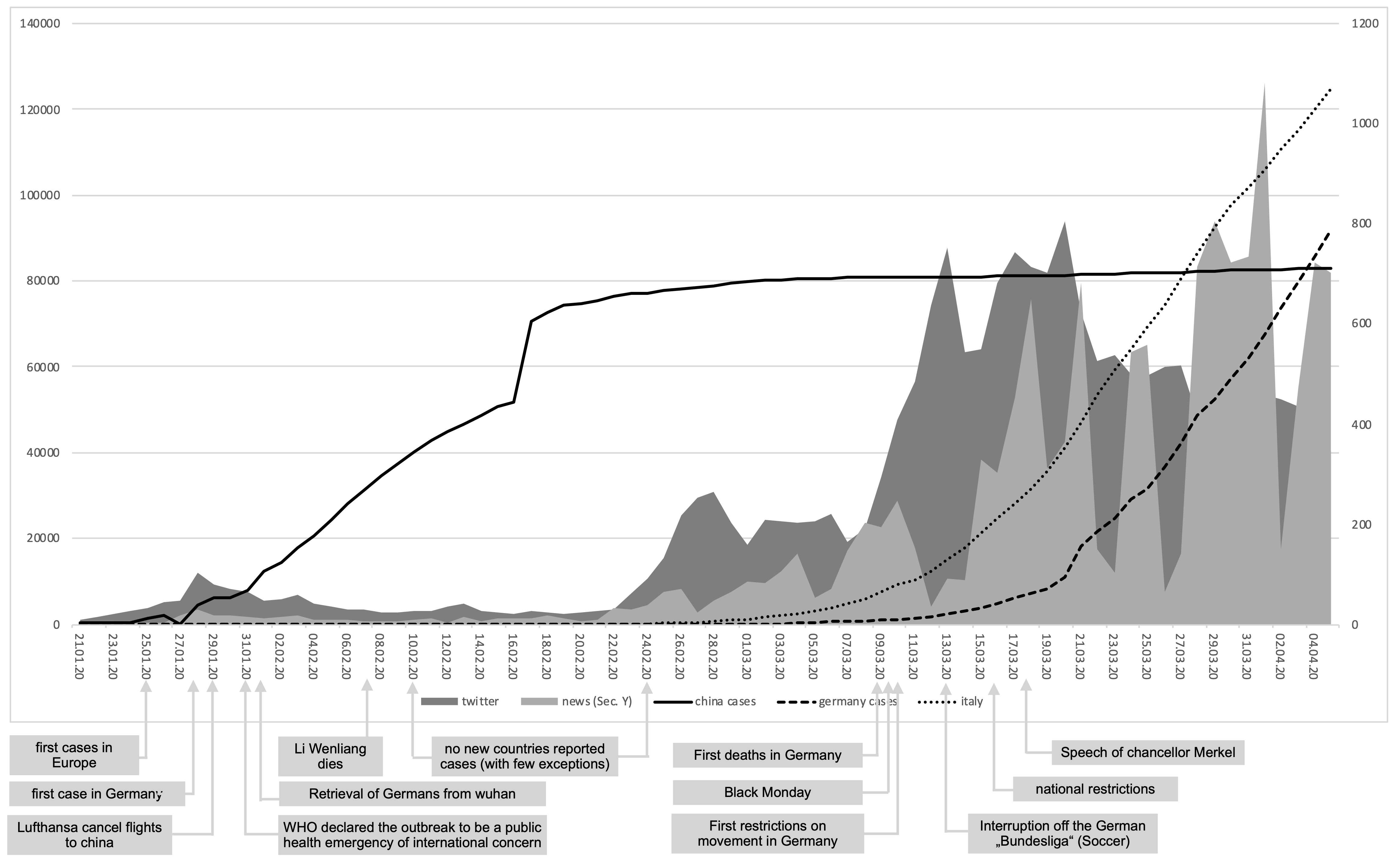
On basis of the visualization, we can arrive at the following preliminary findings:
-
- The news reporting does not reflect the development of reported cases
- Only when the disease reaches European countries, we can see a continuous increase (of what?)
- With the accelerated presence of COVID-19 in Germany, we also observe a strong and sudden increase of news reporting in GermanyThe starting point for this increase seem to be, predominantly, the curfews imposed on public life, which was discussed in all media in comprehensive detail
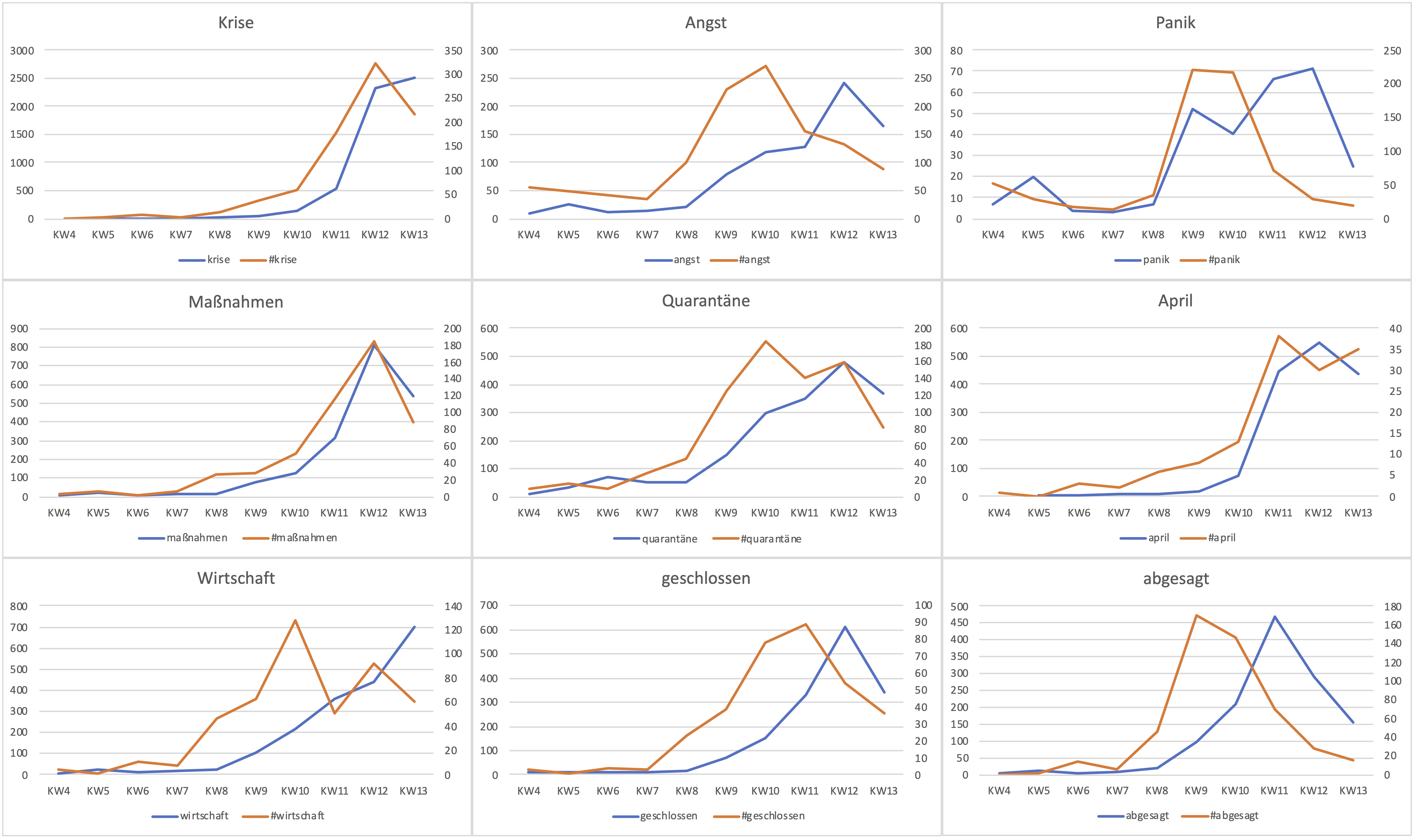
For all terms shown, we suggest that the “topics” on Twitter were discussed earlier than in the traditional media. In the context of the agenda setting theory, we could interpret these distributions at the current time as follows: The traditional media react to the news on Twitter, which allows the latter to set the agenda. However, we suspect (and will examine this in the coming weeks more deeply) a different effect altogether: Specific topics are discussed and commented on Twitter earlier and with more intensity in the beginning, to which the traditional media react with some delay, but not necessarily with dependency on Twitter. We also expect that a differentiated analysis of frequencies by newspaper (BILD, FAZ, and SZ) will be valuable. Once and only when we conduct the qualitative analyses, we will gain the ability to describe how the topics are discussed.
References
Keller, R. (2011): Wissenssoziologische Diskursanalyse. Wiesbaden: VS Verlag Kellner, D. (2018): Medienspektakel und Protest. In: Hoffmann, D.; Winter, R. (ed.): Mediensoziologie. Baden-Baden: Nomos. (pp. 158-173) Neuman, R. W.; Guggenheim, L.; Hang, M. S.; Bae, S. Y. (2014): The Dynamics of Public Attention: Agenda-Setting Theory Meets Big Data. Journal of Communication. 64. 193-214. Schoonenboom, J.;Johnson, B. R. (2017): How to Construct a Mixed Methods Research Design. In: Baur, N.; Kelle, U.; Kuckartz, U. (ed.): Mixed Methods. Wiesbaden: Springer VS. pp107-131. Stier, S.; Posch, L.; Bleier, A.; Strohmaier, M.(2017): When populists become popular: Comparing Facebook use by the right-wing movement Pegida and German political parties. Information, Communication & Society, 20(4):1365-1388