Aktueller Stand unseres Forschungsprojekts
Das Projekt
Wir sind fünf Wissenschaftler*innen aus vier Fachrichtungen (Soziologie, Politikwissenschaften, Informatik und Management) und haben dieses „Corona-Projekt“ am 12.02.2020 gemeinsam begonnen – einige Wochen bevor die ‚chinesische Epidemie‘ zur ‚globalen Pandemie‘ wurde und unsere Beoabchter*innnenposition auch zu einer Betroffenenposition machte.
Trotz großer Fortschritte in der Erhebung, befinden wir uns dennoch am Anfang der Analysen – nicht zuletzt aufgrund der drastischen Zuspitzung der Lage und der damit einhergehenden Vervielfachung des Materials und der darin abgebildeten Dynamiken. Dennoch möchten wir hier einen kleinen Einblick in unsere ersten (Vorab-?)Analysen geben und unseren Erkenntnisverlauf dokumentieren.
Personen: Viola Dombrowski, Oul Han, Marc Hannappel, Matthias Kullbach, Lukas Schmelzeisen
Hintergrund und Forschungsziele
Ausgangspunkt unserer Forschung sind die Ereignisse, die mit der Übermittlung von Informationen über mehrere Fälle vonn Lungenentzündung ungeklärter Herkunft an das Büro der Weltgesundheitsorganisation (WHO) in Beijing, beginnen (siehe WHO Situation Report -1). Innerhalb weniger Wochen entwickelt sich daraus das, was aktuell als Corona-Pandemie (siehe WHO Situation Report 51) weltweit Diskurse und Debatten dominiert.
Zu Beginn der Pandemie entwickelt sich, parallel zu der Ausbreitung der neuartigen Krankheit COVID-19, auch die Lage an Erkenntnissen, Informationen aber auch Spekulationen darüber. Denn dieser nach Keller (2011) als Risikoereignis zu klassifizierende Ausbruch wird von einem nahezu beispiellosen Medienspektakel (Kellner 2018) begleitet. Dies zeigt sich zum einen an der Entwicklung der Masse an Zeitungsartikeln (für die Onlineressorts von BILD, SZ und FAZ ab Mitte März mehr als 600 Stk. pro Tag) sowie in Relation zu anderen Themen der Berichterstattung (bspw. betreffen am 8. April 81 von 118 Artikeln in der FAZ online die Pandemie).

Auch in den sozialen Medien wird das neue Coronavirus – in wahrscheinlich präzedenzloser Vielfalt – zum zentralen Thema. Neben durchaus kreativen Tweets zum Umgang mit der Situation oder Handlungsempfehlungen öffentlicher Behörden, finden sich auch die für Twitter typischen, teils pseudowissenschaftlich, teils verschwörungstheoretisch argumentierenden Akteure. Letztere veranlassten die WHO sogar zur Gründung eines social network teams, welches Falschinformationen gezielt mittels evidenzbasierter Berichterstattung begegnet, nicht ohne die Aufmerksamkeit traditioneller Medien auf die Twitter-basierten Diskussionen zu lenken.
Unser Projekt möchte den Diskurs in den unterschiedlichen Arenen der Öffentlichkeit nach folgenden Zielsetzungen untersuchen:
- Zuerst werden wir den Diskurs thematisch systematisieren und die Entwicklung dieser Themen im Zeitverlauf dokumentieren (Methode: Worthäufigkeiten und ,topic modeling‘ | Theoretischer Bezug: Risikodiskurs nach Keller). Auf diese Weise können wir sichtbar machen, welche Themen zu welchen Zeitpunkten sowohl in den traditionellen Medien als auch auf Twitter entstehen und in welchem Zusammenhang sie mit der jeweils aktuellen Ereignislage (erste Infektionen, erste Todesfälle, Ausgangseinschränkungen, Lebensmittelknappheit etc.) stehen.
- Die Ergebnisse dieser ersten Analysephase verwenden wir, um darauf aufbauend Reziprozitätsstrukturen zwischen traditionellen Medien (hier: BILD, FAZ und SZ), sozialen Netzwerken (hier: Twitter) und „Faktenproduzenten“ (hier: WHO) zu untersuchen, um die Mechanismen verschiedener Informationstransformationsprozesse aufzuzeigen. So wollen wir in den Blick nehmen, welche Institutionen, Organisationen oder Akteure die Themen auf die Agenda des medialen Diskurs „setzen“ (theoretischer Bezug: Agenda Setting Theorie).
- Schließlich untersuchen wir mit Hilfe qualitativer Auswertungsverfahren, wie die verschieden Diskurse von dem „objektiv erfassbaren“ Verlauf der Pandemie beeinflusst werden und vor allem, welche Eigendynamiken sich entwickeln.
Methodik:
Bei der Umsetzung implementieren/verfolgen wir ein ‚explanatory sequential Design‘ nach Schoonenboom und Johnson (2017), kombinieren also quantitative mit qualitativen Methoden in einem iterativen Prozess. Wir verwenden zunächst automatisierte Datenerhebungs- und Auswertungsverfahren, die dem aktuell viel diskutierten Bereich der, Computational Social Science‘ entlehnt sind. Mithilfe eines Python-basierten Web Scraping Algorithmus haben wir einen Datensatz erstellt, der alle Online-Artikel der BILD, SZ und FAZ umfasst, die unter dem Stichwort „corona“ gelistet und seit dem 31.12.2019 erschienen sind. Ferner haben wir alle deutschsprachigen Tweets mit den Hashtags #corona, #coronavirus und #covid19 gesammelt (zur genaueren Beschreibung des Verfahrens siehe Schmelzeisen (2020)).
Für die Auswertung dieser durchaus umfangreichen Datensätze reicht unsere Herangehensweise von der quantitativen Analyse verschiedener Topics und deren Entwicklung über den Verlauf der Pandemie hinweg, bis zur qualitativ-rekonstruktiven Auswertung diskursiver Dynamiken, an auf diese Weise identifizierten Dichtepunkten. Die quantitativen Auswertungen zeigen uns also welche Themen zentral diskutiert wurden, wann diese Themen in beiden Medienformaten aufkamen und in welcher (numerischen) Intensität. Da diese Analysen keine Rückschlüsse über die Art und Weise der öffentlichen Verhandlung der Themen zulassen, die Frage nach dem „wie“ also nicht beantworten können, schließen wir hier mit einer soziologischen Diskursanalyse an.
Das, was wir als Manko algorithmischer Analyseverfahrenwie bspw. dem ‚topic modeling‘ identifizieren können, sollen auf diese Weise mit interpretativen Methoden ausgeglichen werden. So erlauben uns quantitative und algorithmische zwar interessante Verteilungsaussagen (Stier/Posch/Bleier/Strohmaier 2017), aber keinen tieferen Einblick in die Sinnstrukturen von Kommunikationsprozessen. Die quantitativen Auswertungen dienen uns folglich der thematischen und zeitlichen Eingrenzung sowie der Strukturierung des (ansonsten nicht zu bewältigenden) Datenmaterials.
Einblick: Aktuelle Auswertungen
Analyse der tagesgenauen Häufigkeiten von Zeitungsberichten und Tweets in Verbindung mit Ereignissen rund um COVID-19 (Forschungsziel 1):
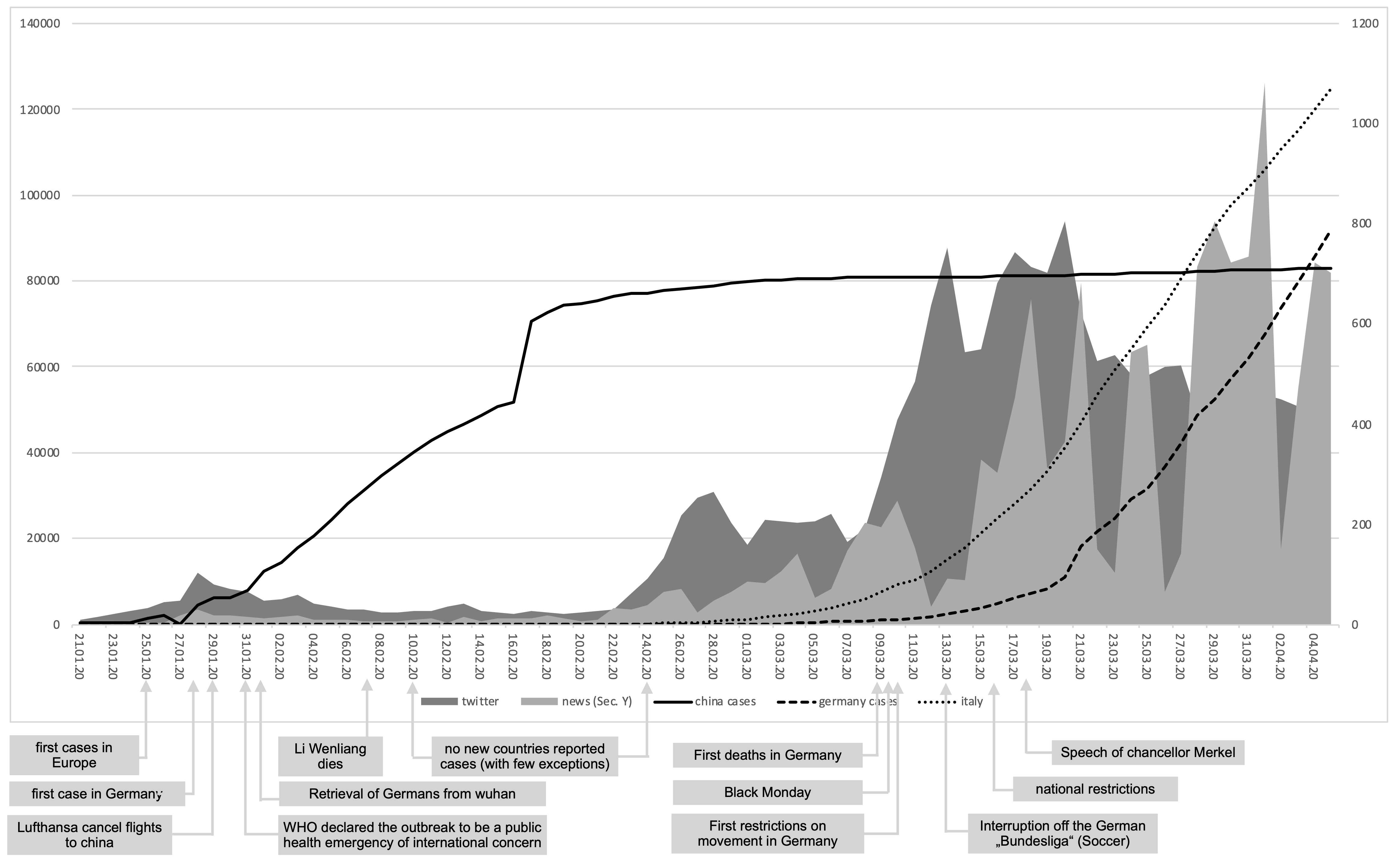
Auf Basis der Abbildung lassen sich folgende (vorläufige) Aussagen treffen:
-
- Die Berichterstattung verläuft nicht parallel zur Entwicklung der Fallzahlen
- Erst als der Krankheitsverlauf europäische Länder erreicht, ist ein kontinuierliches Wachstum festzustellen
- Mit dem beschleunigten Verlauf von COVID-19 in Deutschland, nimmt die Berichterstattung in Deutschland besonders stark und schlagartig zu
- Ausgangspunkt für diesen Anstieg scheinen vor allem die Ausgangsbeschränkungen zu sein, über die ausführlich und umfassend in allen Medien berichtet wurde
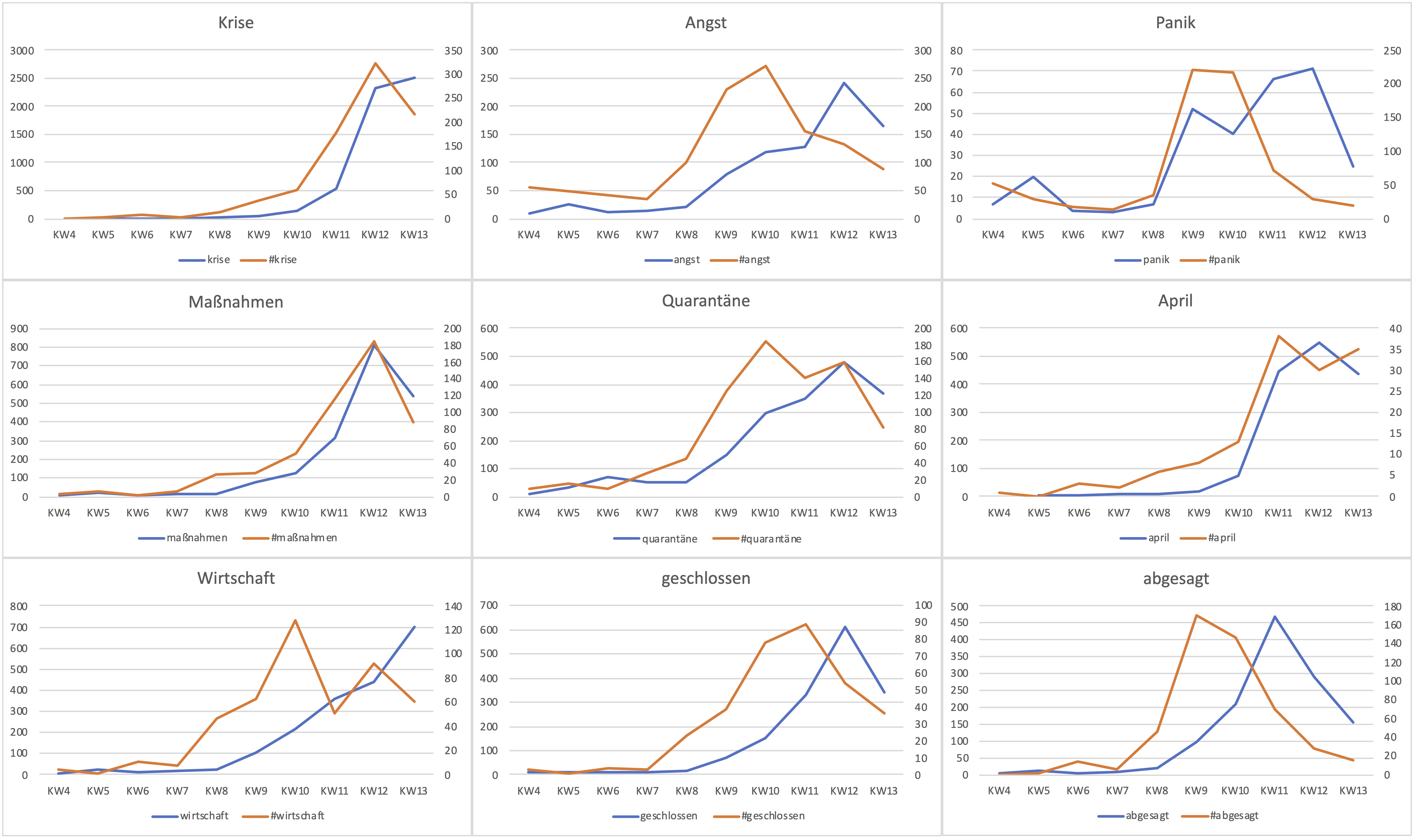
Für alle Begriffe zeigt sich, dass die „Themen“ auf Twitter früher diskutiert wurden, als in den traditionellen Medien. Im Sinne der Agenda Setting Theorie lassen sich diese Verteilungen zum aktuellen Zeitpunkt so interpretieren, dass die traditionellen Medien auf die Twitternachrichten reagieren und letztere somit die Agenda bestimmen. Wir vermuten allerdings (und werden dies in den kommenden Wochen genauer betrachten) einen anderen Effekt: auf Twitter werden bestimmte Themen früher und zunächst intensiver diskutiert oder kommentiert, auf die die traditionellen Medien erst mit etwas Verzögerung – aber nicht notwendigerweise in Abhängigkeit zu Twitter – reagieren. Interessant wäre hier auch eine differenzierte Analyse der Häufigkeiten nach Zeitung (BILD, FAZ und SZ). Antworten auf die Frage, wie die Themen diskutiert werden, werden wir erst mit Hilfe der qualitativen Analysen erhalten.
Literatur
Keller, R. (2011): Wissenssoziologische Diskursanalyse. Wiesbaden: VS Verlag Kellner, D. (2018): Medienspektakel und Protest. In: Hoffmann, D.; Winter, R. (ed.): Mediensoziologie. Baden-Baden: Nomos. (pp. 158-173) Neuman, R. W.; Guggenheim, L.; Hang, M. S.; Bae, S. Y. (2014): The Dynamics of Public Attention: Agenda-Setting Theory Meets Big Data. Journal of Communication. 64. 193-214. Schooneboom, J.;Johnson, B. R. (2017): How to Construct a Mixed Methods Research Design. In: Baur, N.; Kelle, U.; Kuckartz, U. (ed.): Mixed Methods. Wiesbaden: Springer VS. pp107-131. Stier, S.; Posch, L.; Bleier, A.; Strohmaier, M.(2017): When populists become popular: Comparing Facebook use by the right-wing movement Pegida and German political parties. Information, Communication & Society, 20(4):1365-1388